In questo paragrafo spiegheremo come utilizzare l’algoritmo perceptron implementato con Python a partire da un dataset di dati utilizzati principalmente per la studio del machineLearning: l’insieme di caratteristiche che definiscono delle tipologie di fiori Iris.
Iniziamo con l’implementazione del perceptron.py (l’algoritmo spiegato nell’articolo precedente) definendo i metodi fit (per l’apprendimento) e prediction (per la previsione dei nuovi dati)
il dataset iris è una serie di dati, solitamente a matrice, che come righe si ha il numero dei campioni e sulle colonne le caratteristiche per ogni campione.
esempio:
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
.. … … … … …
145 6.7 3.0 5.2 2.3 Iris-virginica
146 6.3 2.5 5.0 1.9 Iris-virginica
147 6.5 3.0 5.2 2.0 Iris-virginica
148 6.2 3.4 5.4 2.3 Iris-virginica
149 5.9 3.0 5.1 1.8 Iris-virginica
Il problema che vogliamo risolvere è: dato un campione di dati con determinate caratteristiche, a quale classe corrisponde? Iris-setosa oppure Iris-virginica?
la prima cosa da fare è inputare all’algoritmo perceptron il set di dati.
from perceptron import Perceptron
pn = Perceptron(0.1, 10)
pn.fit(X, y)
print(“dataset”,df)
print(“target”,y)
print(“training”,X)
print(“errors”,pn.errors)
print(“weight”,pn.weight)
Una volta importato l’algoritmo perceptron utilizziamo la funzione di apprendimento “fit” imputando il set di dati di training “X” ed il target “y” (classificazione attesa). Lanciamo il codice ed il risultato è il seguente:
target [-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
-1 -1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1]
Per comodità abbiamo classificato la prima tipologia di Iris in -1 e la seconda in 1. Il dataset. Come training dei dati prendiamo i primi 100 campioni.
Mostriamo il risultato sulle dashboard di nodered ed interpretiamo i risultati.
usiamo un grafico a dispersione per visualizzare il dataset inziale:
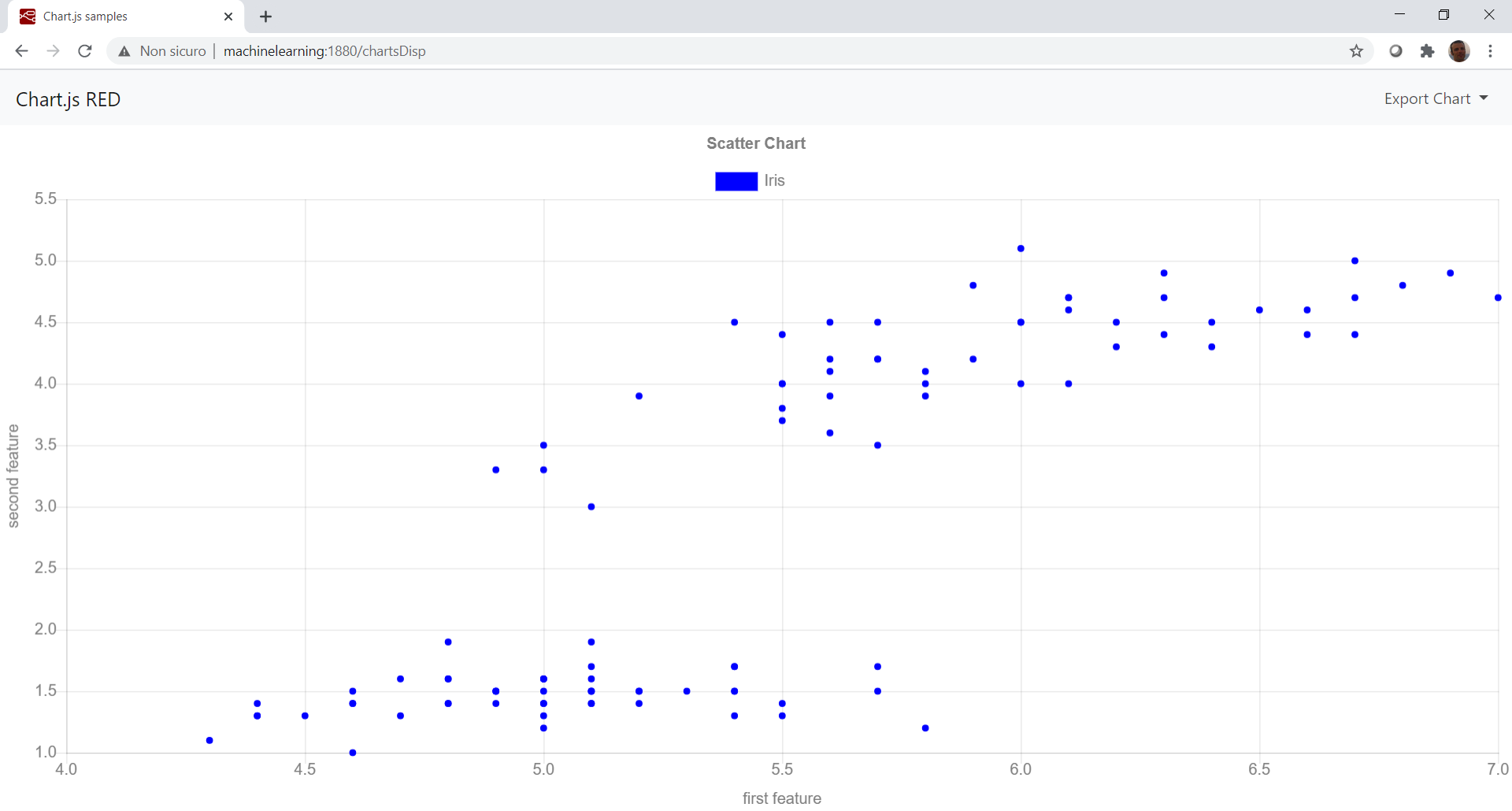
Come si vede nel grafico abbiamo una netta distinzione della classificazione binaria. La parte alta sono campioni relativi al target -1 mentre la parte bassa sono campioni relativi alla classe 1.
Proviamo ad importare questo dataset in modo da addestrare l’algoritmo. Per capire la precisione di classificazione dell’algoritmo dobbiamo osservare il grafico degli errori ad ogni step di apprendimento. L’algoritmo, inoltre, accetta due parametri in ingresso: il numero di iterazioni (i cicli nei quali si aggiornano i pesi) ed il tasso di apprendimento. Il risultato è il seguente:
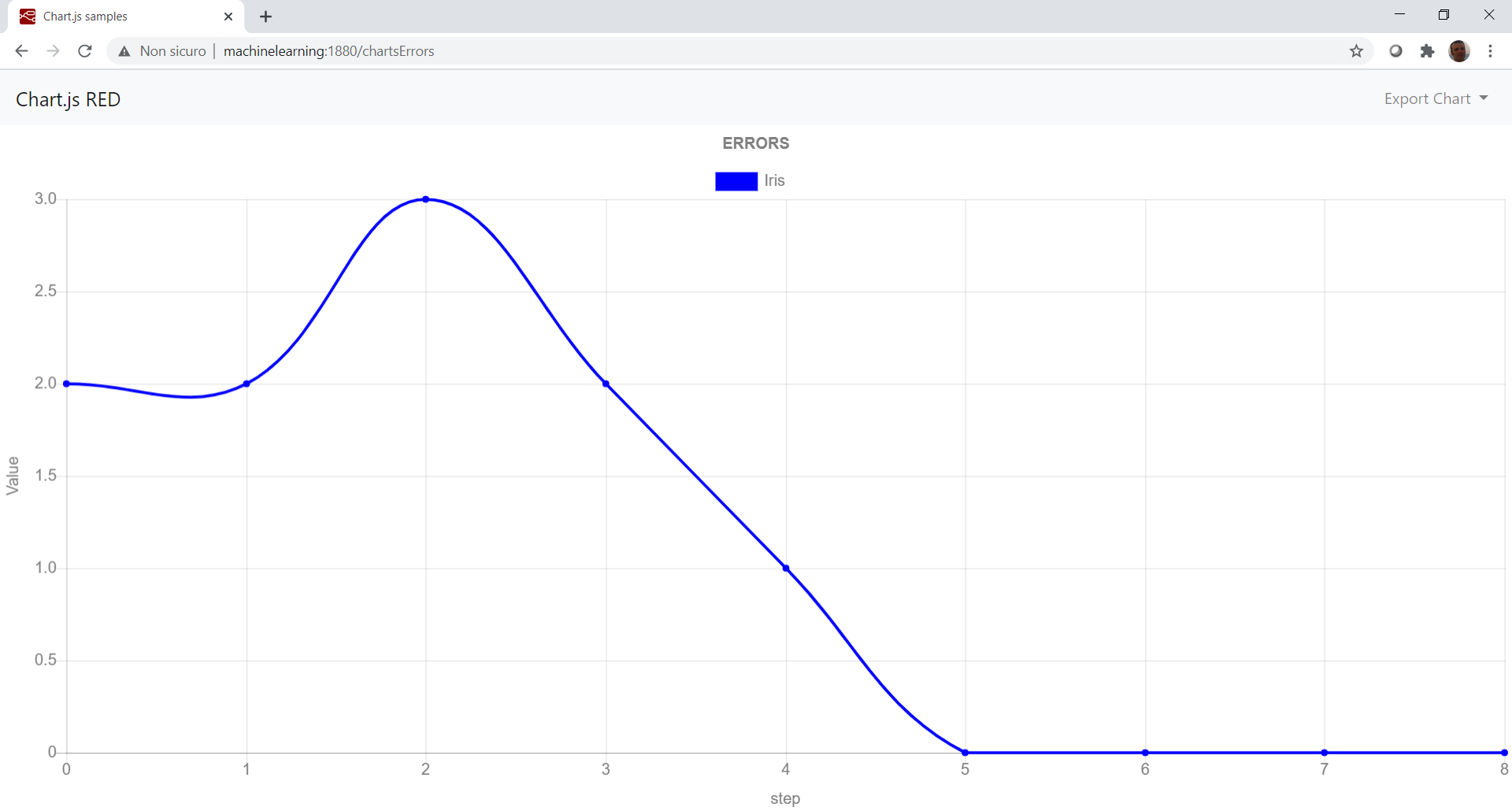
Notiamo che dalla quinta iterazione l’errore si azzera, ciò vuol dire che già dalla quinta iterazione l’algoritmo è in grado di predire il risultato per ogni nuovo campione in ingresso.
Proviamo quindi la funzione predict con il campione: Y = np.array([4,1]), ovvero caratteristiche 4 e 1. L’algoritmo ci dovrà predire se sono caratteristiche di Iris-setosa oppure Iris-virginica.
- print(“predict: ” perceptron.predict(Y))–> predict: -1
- proviamo con Y = np.array([4,1]), predict: 1
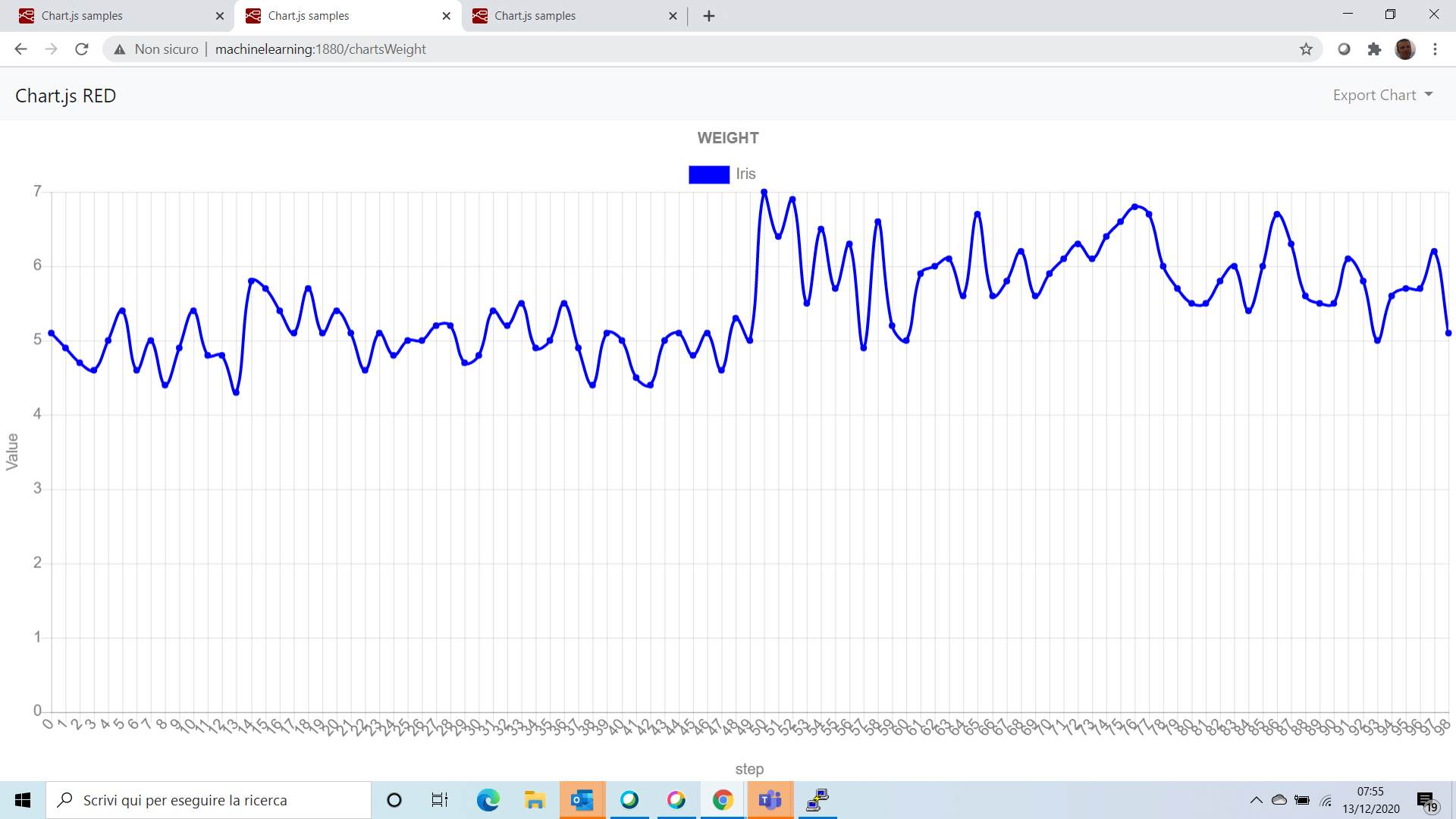
Un altro grafico interessante è l’andamento dei pesi ad ogni iterazione. Con questo grafico visualizziamo passo passo la correzione che l’algoritmo esegue sui pesi per migliorare la predizione.