
Prendendo spunto dal paragrafo precedente per ottimizzare l’algoritmo di Adaline in modo che la funzione costo venga minimizzata in maniera più veloce allora è possibile standardizzare l’intero dataset con la normalizzazione delle caratteristiche.
In che modo possiamo normalizzare? usando la distribuzione normale standard. la distribuzione normale standard prevede
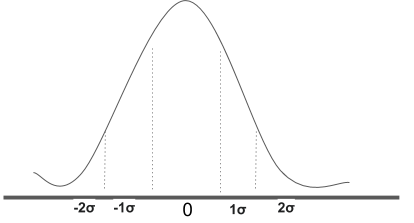
Per normalizzare il dataset basta prendere ogni caratteristica, sottrarla per la media della distribuzione normale μ e dividere tutto per la deviazione standard σ
Ad esempio, per standardizzare la caratteristica j-esima è necessario prima sottrarre la media μj poi dividere per σj .
x‘j = (xj – μj)/σj
Addestriamo ora lo stesso algoritmo Adaline utilizzato nel paragrafo precedente con il dataset normalizzato. La libreria numPy ha già funzioni per calcolare la deviazione standard e la media.
Anzitutto vediamo nel grafico i valori normalizzati,
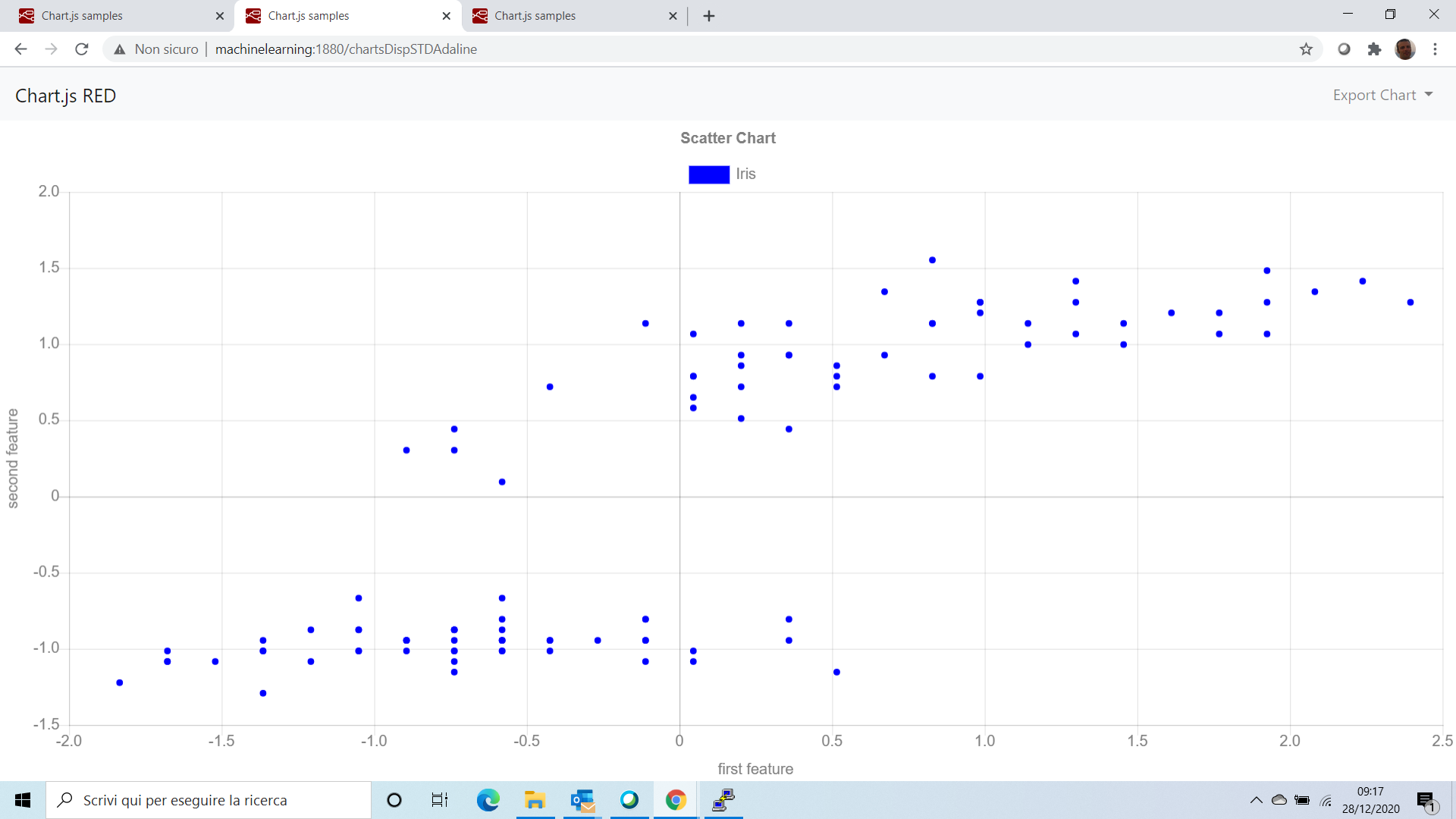
Addestriamo l’algoritmo con questi dati, dopo di che, osserviamo il grafico dei costi
pn = Adaline(0.01, 15)
pn.fit(X_std, y)
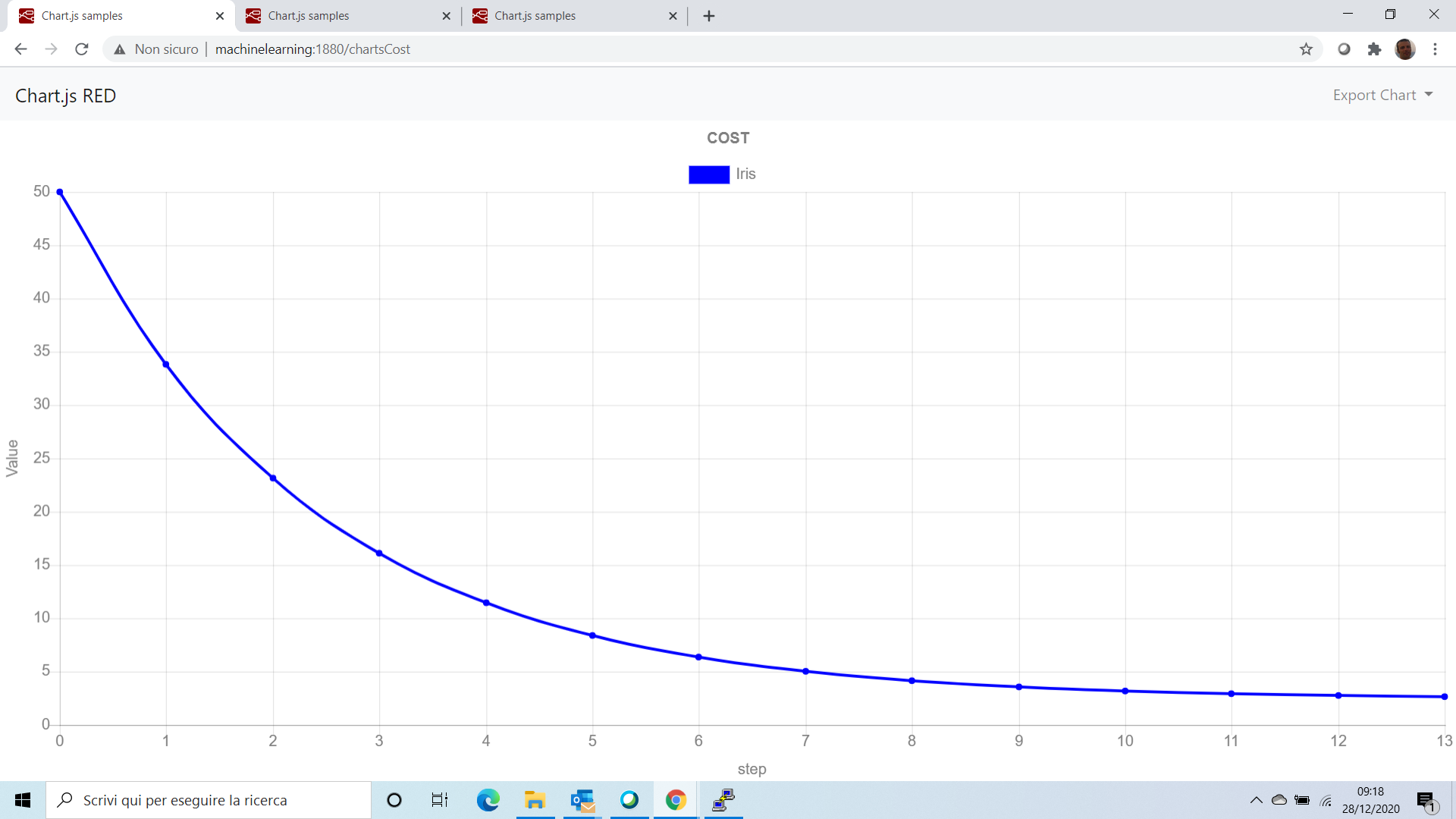
Il grafico mostra chiaramente la convergenza della funzione dei costi a fronte di un dataset normalizzato.
Giusto per fare un confronto mostriamo lo stesso grafico dei costi addestrando l’algoritmo con il dataset non normalizzato.
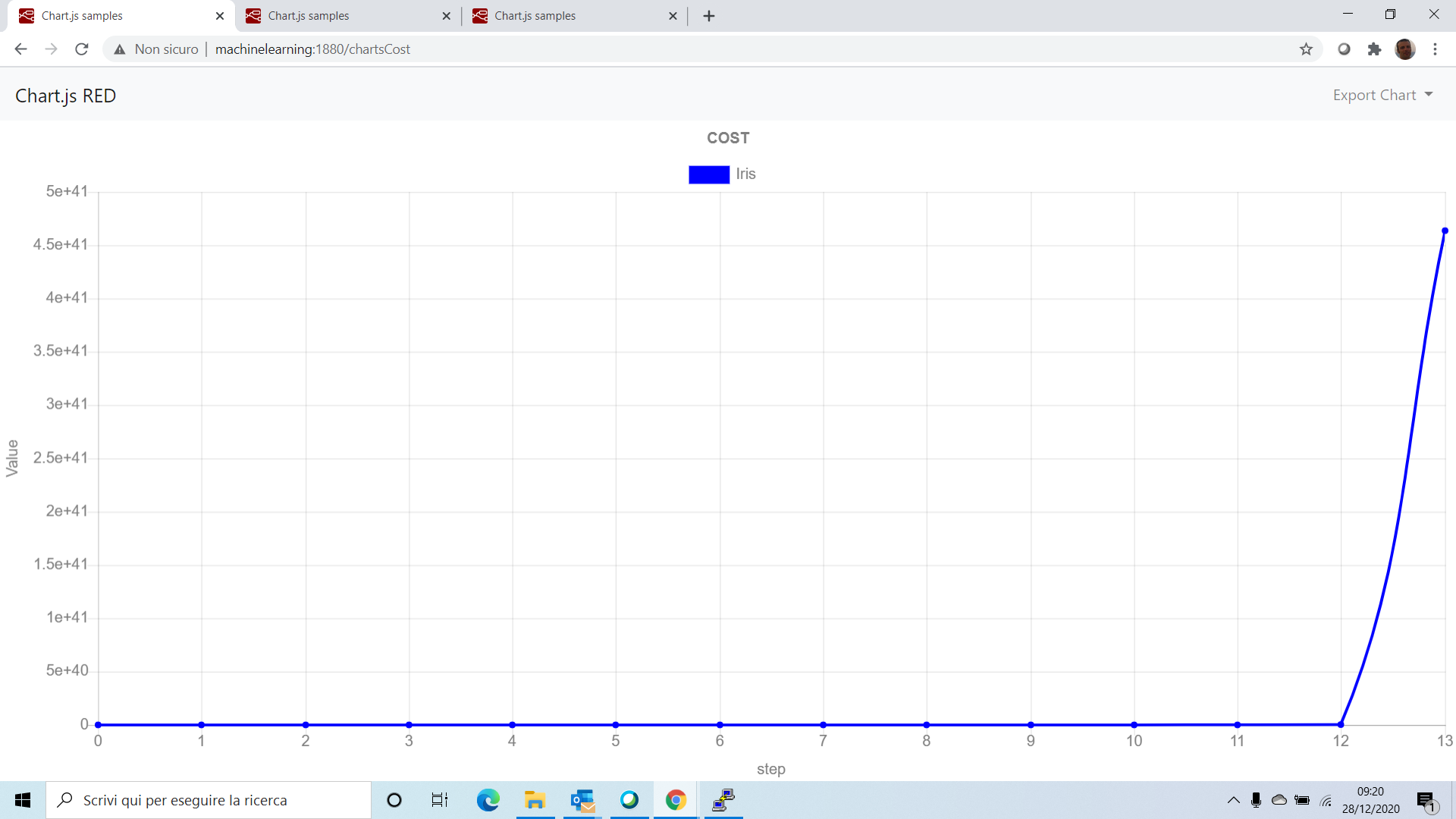
Come volevasi dimostrare, la funzione di costo viene nettamente ottimizzata utilizzando il dataset normalizzato.