Nel precedente articolo abbiamo capito come si crea una blockchain privata Ethereum.
In questo articolo creeremo un semplice smartcontract, con linguaggio solidity, che restituisce semplicemente un numero e consente di sommare o sottrarre il numero per 10.
Utilizzeremo, a tale scopo, un editor online remix che ci consente di fare debug del codice e di renderlo attivo nella blockchain.
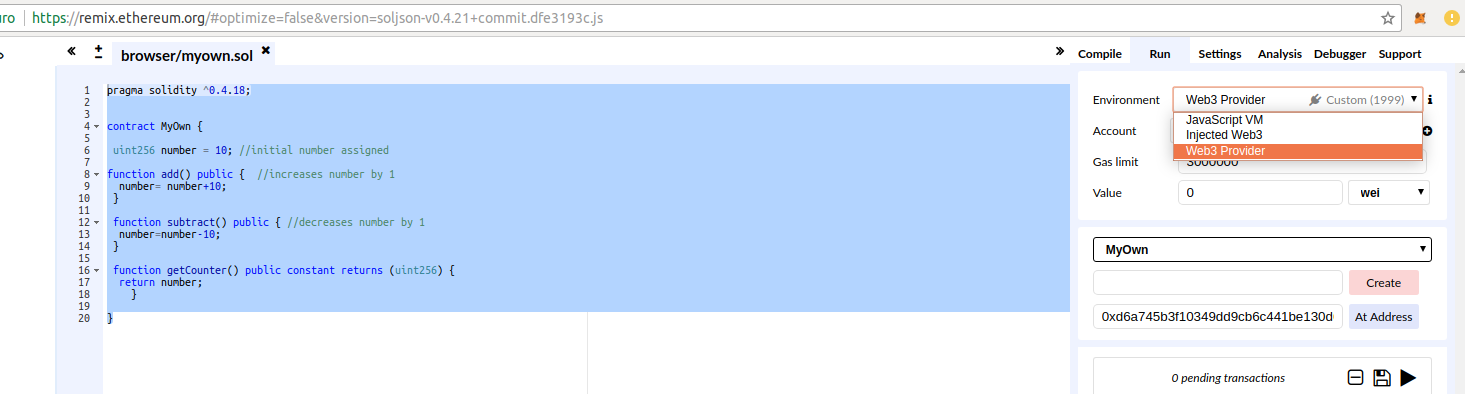
Accedendo su remix possiamo creare un nuovo progetto che chiameremo myown.sol.
Remix consente anche la compilazione del codice e la creazione del contratto intelligente sulla nostra blockchain privata. Per fare questo è necessario selezionare la voce run-> environment->web3 provider e specificare l’endpoint http://localhost:8545.
L’accesso alla rete privata tramite remix sarà possibile soltanto se il nodo miner è stato lanciato con questo parametro –rpccorsdomain “*” .
Una volta connessi con remix è possibile visualizzare subito la connessione alla nostra networkId 1999 ed il nostro account con il valore eth assegnato.
A questo punto potete fare copia incolla dal codice qui sotto.
pragma solidity ^0.4.18;
contract MyOwn {
uint256 number = 10; //initial number assigned
function add() public { //increases number by 10
number= number+10;
}
function subtract() public { //decreases number by 10
number=number-10;
}
function getCounter() public constant returns (uint256) {
return number;
}
}
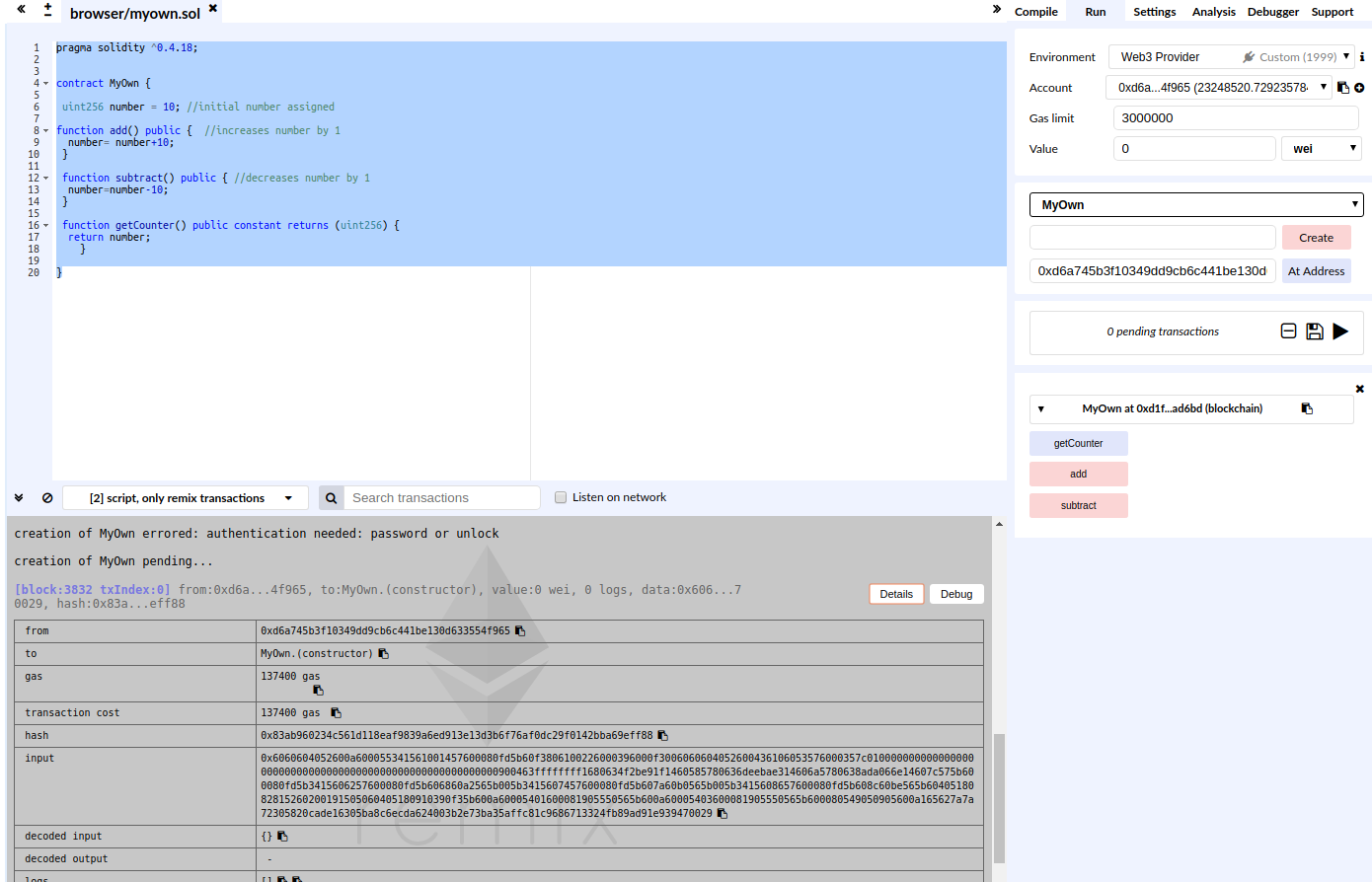
E’ possibile attivare l’autocompile sotto la scheda compile e, se non ci sono problemi, è possibile attivare il contratto appena creato.
per creare il contratto è necessario sbloccare l’account sulla geth console (guarda l’articolo precedente) e premere su create (pulsante in rosso). Sul campo at address inseriamo il nostro account che abbiamo appena sbloccato.
web3.personal.unlockAccount(eth.coinbase)
Il risultato è come in figura
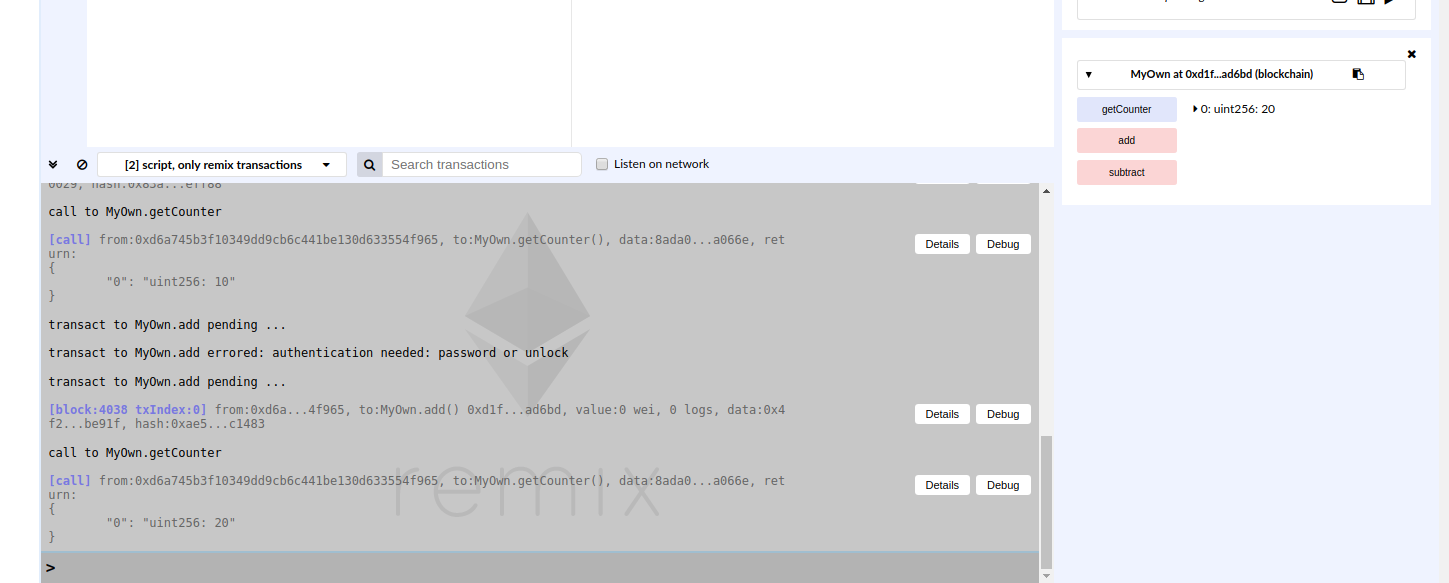
Come si può vedere, remix ci presenta le funzioni pubbliche costruite nel contratto: add, subtract, getCounter. A questo punto possiamo premere le singole funzioni e visualizzare il risultato.
Si noti che il numero iniziale è 10 come impostato staticamente nel codice, se premiamo add il numero aumenta di 10, se premiamo subctract il numero diminuisce di 10.
Con l’articolo precedente abbiamo capito come funziona la blockchain e come potrebbe cambiare in futuro internet.
Con questo articolo spieghiamo come può essere sfruttata la blockchain nell’ottica di creare applicazioni decentralizzate. Ovvero che non necessitano di un server centrale per il funzionamento.
Un progetto molto interessante è Ethereum e permette appunto la creazione di applicazioni decentralizzate di qualsiasi tipo.
Per capire fino in fondo Ethereum iniziamo a studiarlo installandone un’istanza privata.
Per installare Ethereum seguiamo queste istruzioni che ci consentiranno di installare sul nostro ambiente linux geth.
Per prima cosa generiamo un account di minatore, ovvero, colui che elaborerà l’algoritmo per creare gli ethereum coins. La creazione dell’account produrrà una coppia di chiavi (pubblica e privata). Questa coppia di chiavi viene inserita all’interno della cartella data_dir/keystore. Qualsiasi cosa di persistente verrà scritta nella cartella data_dir.
Una volta creato l’account viene mostrato a video anche l’indirizzo del nodo address_number.
#creiamo la cartella principale e la cartella 'data' nella quale viene conservata il keystore
>mkdir myown
>mkdir myown/data
#creiamo il nuovo account nella cartella creata
>geth account new --datadir /home/studio/blockchain/myown/data/
Address: {cb0f0fc732ad30b0------17e59122e693bb585}
blocco genesis
Ora che abbiamo l’account possiamo creare il primo blocco ethereum. Chiamato genesis. Ogni blockchain di ethereum ha il suo primo blocco genesi. Per far sì che la nostra blockchain non vada in conflitto con altre blockchain dobbiamo modificare i valori networkId di default.
#genesis.json
{
"config": {
"chainId": 1999, #networkId
"homesteadBlock": 0,
"eip155Block": 0,
"eip158Block": 0
},
"difficulty": "200000000", #valore di difficoltà applicata per la scoperta di questo blocco
"gasLimit": "2100000", #limite di gas (ethereum) per eseguire tutte le le transazioni nel blocco
"alloc": { #preallocazione ethereum sul primo account
"cb0f0fc732ad30b021c52-----122e693bb585": { "balance": "400000" }
}
}
inizializzazione genesis e start mining
L’operazione di mining consente la generazione di ethereum in base a calcoli matematici. Di seguito un esempio…
>geth --datadir /home/studio/blockchain/myown/data init genesis.json
INFO [03-10|10:47:41] Maximum peer count ETH=25 LES=0 total=25
INFO [03-10|10:47:41] Allocated cache and file handles database=/home/studio/blockchain/myown/geth/chaindata cache=16 handles=16
INFO [03-10|10:47:41] Writing custom genesis block
INFO [03-10|10:47:41] Persisted trie from memory database nodes=1 size=195.00B time=75.389µs gcnodes=0 gcsize=0.00B gctime=0s livenodes=1 livesize=0.00B
INFO [03-10|10:47:41] Successfully wrote genesis state database=chaindata hash=aa6b0d…0d8207
INFO [03-10|10:47:41] Allocated cache and file handles database=/home/studio/blockchain/myown/geth/lightchaindata cache=16 handles=16
INFO [03-10|10:47:41] Writing custom genesis block
INFO [03-10|10:47:41] Persisted trie from memory database nodes=1 size=195.00B time=58.634µs gcnodes=0 gcsize=0.00B gctime=0s livenodes=1 livesize=0.00B
INFO [03-10|10:47:41] Successfully wrote genesis state database=lightchaindata hash=aa6b0d…0d8207
avvio blockchain con nodo da minatore. Il mining è possibile farlo anche dalla console.
geth --mine --rpc --rpcaddr 0.0.0.0 --rpccorsdomain "*" --networkid 1999 --datadir /home/studio/blockchain/myown/data/
Initialised chain configuration config="{ChainID: 1 Homestead: 1150000 DAO: 1920000 DAOSupport: true EIP150: 2463000 EIP155: 2675000 EIP158: 2675000 Byzantium: 4370000 Engine: ethash}"
INFO [03-10|10:54:03] Disk storage enabled for ethash caches dir=/home/studio/blockchain/myown/data/geth/ethash count=3
INFO [03-10|10:54:03] Disk storage enabled for ethash DAGs dir=/home/studio/.ethash count=2
INFO [03-10|10:54:03] Initialising Ethereum protocol versions="[63 62]" network=1999
colleghiamo la geth console
per collegare la geth console con il nodo di mining appena creato basta applicare il seguente script su un altro terminale
>geth --datadir /home/studio/blockchain/myown/data/ attach ipc:/home/studio/blockchain/myown/data/geth.ipc
instance: Geth/v1.8.1-stable-1e67410e/linux-amd64/go1.9.4
coinbase: 0xcb0f0fc732ad30b021c52e--------22e693bb585
at block: 0 (Thu, 01 Jan 1970 01:00:00 CET)
datadir: /home/studio/blockchain/myown/data
modules: admin:1.0 debug:1.0 eth:1.0 miner:1.0 net:1.0 personal:1.0 rpc:1.0 txpool:1.0 web3:1.0
Welcome to the Geth JavaScript console!
in questo caso la console si connette al nodo attraverso pipe ipc (interprocesse) che funziona sul computer locale.
Dalla consolle possiamo eseguire le prime istruzioni
Letteralmente blockchain significa catena di blocchi. Per quale motivo una catena di blocchi sarà la rete del futuro?
Per rispondere a questa domanda dobbiamo prima di tutto conoscere come funziona la tecnologia blockchain.
Fino ad oggi quando pensiamo ad internet generalmente pensiamo ad una rete centralizzata. Ovvero, il mio PC (client) si connette al server in modo da richiede informazioni o fare altri tipi di operazioni come: creare bonifici, acquistare, scrivere articoli…
Quando sentiamo parlare di blockchain si intende un tipologia di rete in cui viene meno la centralizzazione delle informazioni. Infatti, la basedati è distribuita e decentralizzata per tutti i nodi della rete.
In realtà, in qualche occasione abbiamo già sentito parlare di rete distribuita: la rete peer to peer. Questa rete è usata sopratutto per la condivisione dei file in cui ogni nodo della rete può ricevere ed inviare informazioni ad altri nodi della rete senza che ci sia alcun nodo che faccia da intermediario.
Nel caso della blockchain ogni nodo possiede lo stesso database presente su tutti gli altri nodi e, grazie a particolari tecniche di crittografia, ogni informazione (chiamata transazione) viene inserita in blocchi e viene distribuita su tutti i nodi della rete. Una delle peculiarità della blockchain è che l’informazione non è duplicabile.
Com’è possibile non duplicare le informazioni su internet? ad esempio un e-book o una canzone?
Per rispondere a queste domande bisognerebbe avere alcune nozioni base di crittografia. In particolare:
Questa funzione ha due caratteristiche principali:
trasforma qualsiasi tipo di informazione digitale in una sequenza numerica di 256 bits. Potete fare delle prove con esempi testuali su questo link. Il risultato della funzione hash è ciò che verrà inserito in una transazione di un blocco della blockchain. Quindi, posso convertire un file di 10GB in un file testuale da 256bits
Se utilizzo questa funzione su un’immagine otterrò una sequenza alfanumerica; se all’immagine cambio il metadato di pubblicazione allora otterrò un’altra sequenza alfanumerica completamente diversa. Se qualcuno copia la mia immagine allora il file copiato avrà un hash completamente diverso dall’originale.
Crittografia asimmetrica con chiave pubblica-privata
Ogni membro della blockchain ha una chiave pubblica e privata. Se volessi trasferire un’immagine di mia proprietà ad un destinatario allora posso agire in questo modo:
Con la chiave privata posso crittografare, ad esempio, l’hash della mia immagine in modo da firmarla digitalmente. Durante la transazione invio al mio destinatario, oltre all’hash firmato, anche la chiave pubblica (la chiave pubblica è generata attraverso una funzione complessa logaritmica dalla chiave privata. Dalla chiave pubblica è ad oggi impossibile risalire alla chiave privata). Il mio destinatario può, a questo punto, decriptografare l’hash con la mia chiave pubblica (in questo modo riconosce che l’immagine è di mia proprietà) e confrontare l’hash ottenuto con l’hash dell’immagine stessa in modo da verificare l’autenticità del file.
Come si applica la crittografia in una blockchain?
Ogni transazione avrà sempre un elemento in input ed uno in output. Se io volessi inviare un file da A a B, firmo digitalmente il file con la chiave privata di A e poi cripto la transazione con la chiave pubblica di B in modo tale che solo B può ricevere il file. A questo punto B decripta il file con la chiave pubblica di A.
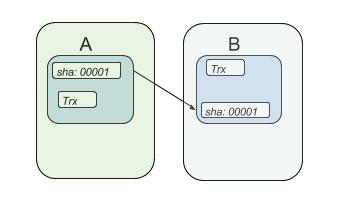
linked block
Ogni blocco della rete è rappresentato univocamente da un’hash. Ad esempio supponiamo che A è collegato a B. A è rappresentato da 0001, B possiede (nel campo relativo all’hash precedente) 0001. A e B risultano collegati tra loro e questo tipo di relazione fa sì che si rispetti l’integrità. Ciò vuol dire che ogni modifica al blocco A modificherà il suo codice hash e romperà la catena con il blocco B.
In generale, ogni blocco della catena contiene un puntatorehash come collegamento al blocco precedente, un timestamp e i dati della transazione.
Come si creano i blocchi?
i blocchi non sono altro che una collezione di transazioni create dagli utenti della blockchain. Per essere utente della blockchain basta possedere un portafoglio (o wallet, ce ne sono diversi in giro). Una volta creato il proprio wallet viene fornita la chiave pubblica e la chiave privata (che non deve essere assolutamente condivisa con nessuno).
Tutte le transazioni create da chiunque abbia un portafoglio (wallet) vengono raccolte in un blocco (al quale verrà assegnato un hash). Questo codice verrà poi inserito nel blocco successivo. Ogni transazione subirà, prima di accedere al blocco, una serie di controlli da parte dei nodi completi della rete in modo da verificarne la validità (i nodi completi sono nodi che hanno tutta la blockchain nel proprio storage). Una volta generato il blocco e convalidato le checksum di tutte le transazioni l’algoritmo proof-of-work garantisce che il nodo sia accettato da tutti i nodi della rete.
Chi sono i miners?
I miners sono nodi della rete che assicurano la validità ed il corretto funzionamento della blockchain. Tecnicamente pubblicano di continuo blocchi nuovi della blockchain con le transazioni che hanno appena verificato (1MB X 2000 transazioni). una volta che il miner pubblica un nodo riceve una ricompensa (bitcoin o altre criptovalute). I miners sono tra loro in competizione: chi produce blocchi per prima riceve ricompense maggiori. La velocità di calcolo e la banda di rete sono determinanti nella generazione dei blocchi.
La tecnologia appena descritta si sta evolvendo verso una nuova generazione di applicazioni web3.0. Ethereum è un piattaforma basata su blockchain che promette (oltre alla generazione di criptovalute) anche di poter creare applicazioni distribuite (senza un server centrale) DAPPS.
Quindi, se associamo le potenzialità della blockchain con le applicazioni distribuite potremmo aprire le porte ad una vasta gamma di applicazioni future che non avranno più bisogno di una centralizzazione delle informazioni o di una verifica di un ente terzo.
In questo tutorial spiegheremo come poter implementare un sistema domotico d’avanguardia utilizzando le più moderne tecnologie.
Per maggiori informazioni contatta l'esperto che collabora con noiDitta Pietrantuono PietroInstallazione, Manutenzione e Riparazione Impianti Elettrici/Domoticiinfo@informaticagestionale.itcell. 339.2605170
Utilizziamo la seguente lista di tecnologie hardware e software:
una volta scaricata l’immagine la installiamo su SD CARD seguendo le seguenti istruzioni:
dopo aver inserito la scheda nel PC, formattare la scheda SD in FAT32
con windows o mac utilizzare uno dei tanti programmi di preparazione dischi di avvio
con ubuntu installare l’immagine nella partizione della scheda SD:
sudo dd if=/imagePosition/image.img.xz of=/dev/sd* (Attenzione! sostituire * con la partizione esatta della scheda SD, altrimenti, rischiate di cancellare l'intero disco del PC)
per fare in modo che lo schermo si adatti perfettamente con lo schermo da 7 pollici si deve modificare il file /boot/config.txt sulla partizione della scheda SD.
7” raspberry LCD preparation
dopo aver preparato lo schermo LCD da 7 pollici con il raspberry inserire nell’apposita fessura la scheda SD opportunamente preparata (ricorda di cambiare la risoluzione sulla scheda nel file /boot/config.txt)
socket SD card
una volta collegato il raspberry con la rete ethernet (o wireless), accenderlo, aspettare che raspbian si avvii correttamente, e da questo momento, collegarsi al raspberry direttamente attraverso SSH di un’altro device (a meno che non si voglia continuare la configurazione direttamente sul raspberry stesso). ssh pi@ip_public
una volta connessi al raspberry inseriamo questi comandi per aggiornare ed aggiungere nuovi software
sudo apt-get update sudo apt-get upgrade
sudo apt-get install screen mc vim git htop
continuare l’installazione seguendo queste istruzioni
una volta installato OpenHab, è possibile iniziare la configurazione vera e propria installando gli addons preferiti (esempio zwave) e configurando gli items che vengono automaticamente generati durante il rilevamento.
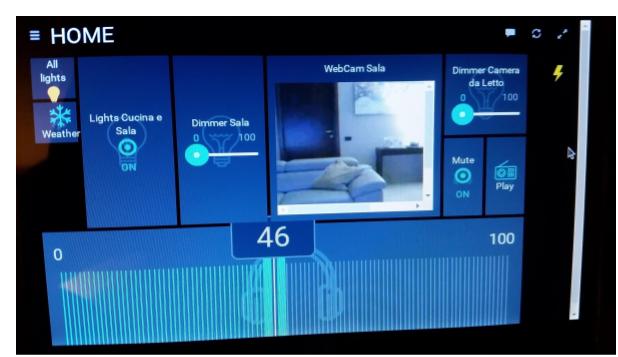
OpenHab utilizza diversi sistemi dashboard. Nel nostro caso il sistema domotico appena configurato si presenta come in figura.
tasto di accensione di tutte le luci
dimmer presente in sala
dimmer presente in camera da letto
webcam in sala
barra per il controllo del volume del mediacenter
play/pause mediacenter
tasto muto mediacenter
Al termine della configurazione possiamo associare al nostro terminale tutti i dispositivi elencati sopra:
colleghiamo la webcam con la porta USB del raspberry
colleghiamo i punti luce, i sensori, il termostato e l’allarme con il server zwave direttamente dalla dashboard di openhab
il sistema può essere integrabile con altri dispositivi quali:
sensore di presenza delle persone autorizzate
sensori porta-finestra antifurto
sensori volumetrici e così via
Questo tutorial era solo un esempio,
se desiderate anche voi un impianto domotico ma non avete le competenze tecniche allora provate a contattare gli esperti che collaborano con noi:
Ditta Pietrantuono PietroInstallazione, Manutenzione e Riparazione Impianti Elettrici/Domoticiinfo@informaticagestionale.it
cell. 339.2605170
oltre alla configurazione ed alla predisposizione del pannello di controllo ci si occuperà anche della personalizzazione dei collegamenti elettrici con l’impianto di casa.
InformaticaGestionale.it propone ai suoi lettori il nuovo servizio online che sfrutta il teorema di Bayes per fare predizioni di qualsiasi tipo grazie ad un set di dati storici eseguiti su specifici attributi. L’obiettivo è predire un determinato target o valore a partire da un nuovo set di attributi.
Questo può essere utile in moltissimi campi di applicazione: dal sociale alla medicina, dalla manutenzione alla produzione industriale.
Ecco una carrellata di esempi:
lotti di produzione PC difettosi sulla base di attributi come temperatura (alta, media, bassa), velocità di produzione, tipo PC (standard, custom), qualità materiali (ottimo, scarso, buono). Riusciamo quindi ad identificare se un lotto sarà difettoso oppure no.
l’acquisto di un prodotto da parte di un potenziale cliente in base ad attributi quali dimensioni azienda (piccola, media o grossa), tipologia azienda (servizi o manifatturiera), prezzo del prodotto.
capire se una persona ha una determinata malattia sulla base di attributi quali sintomi, sesso, esami che determinano se l’individuo è malato oppure no.
capire se un macchinario industriale ha bisogno di manutenzione (in modo da prevenire eventuali guasti) sulla base del tempo di funzionamento, velocità di produzione, complessità del prodotto (semplice, medio, complesso).
…
Il modello matematico utilizzato è basato su record storici che sono stati preventivamente inseriti (training_set). In base a questi record è possibile predire una determinata condizione preventivamente inserita nel testing_set.
Il calcolo della probabilità condizionata per ognuna delle casistiche determina la probabilità che si verifichi l’evento 1 oppure l’evento 2.
La predizione verrà orientata sull’evento con più alta probabilità.
ad esempio:
Data la seguente traingin table, vogliamo predire il valore della riga segnata in giallo (testing table)
TIPO AUTO
TIPO GUIDA
TIPO STRADA
KM PERCORSI
PREZZO AUTO
TARGET
SUV
SPORTIVA
MISTO
4000
65000
NO MANUTENZIONE
UTILITARIA
PASSEGGIO
CITTA
80000
30000
MANUTENZIONE
SUV
PASSEGGIO
MISTO
15000
80000
NO MANUTENZIONE
UTILITARIA
SPORTIVA
CITTA
8000
20000
MANUTENZIONE
MONOVOLUME
SPORTIVA
MISTO
4000
65000
NO MANUTENZIONE
MONOVOLUME
LAVORO
CITTA
80000
40000
NO MANUTENZIONE
SUV
LAVORO
MISTO
250000
120000
MANUTENZIONE
UTILITARIA
LAVORO
AUTOSTRADA
70000
10000
MANUTENZIONE
UTILITARIA
SPORTIVA
MISTO
200000
12000
TO PREDICT
Secondo Naive Bayes il valore predetto è MANUTENZIONE : 3.6747338165603E-13
Se, invece di mettere 200.000 km percorsi mettiamo solo 20.000km allora la macchina risulta in NO MANUTENZIONE
qui l’esempio, potete provare a cambiare il testing set e visualizzare il valore predetto: ESEMPIO1
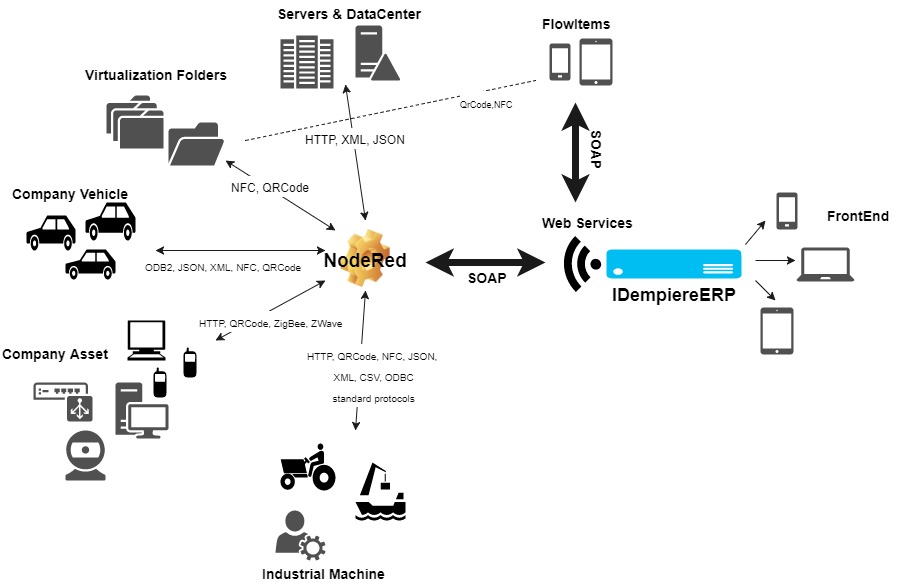
IdempiereIot prevede la gestione “intelligente” di questi dispositivi:
Virtualizzazione dei beni aziendali: ogni bene aziendale può essere associato su Idempiere: è possibile categorizzarlo, inserire informazioni aggiuntive (es. data prossimo controllo), link ad allegati…
Gestione dello stato del bene: (es. occupato, disponibile, guasto…)
Interazione con altri beni aziendali: (es. se un server lavora per diversi giorni con temperature ambiente troppo elevate allora si presume, in base ai dati storici, che si danneggi nel giro di poco tempo. A questo punto il “motore centrale” invia un alert all’operatore ed invia un segnale al termostato per abbassare automaticamente la temperatura).
Interazione con il sistema ERP: es.associazione di un bene ad un dipendente (es. assegnazione di un notebook aziendale), condivisione di un bene con più dipendenti (es. macchina industriale), tempo di utilizzo di un bene da parte di un dipendente, scannerizzazione tag cespite direttamente sul “bene”…
Storicizzazione di tutti gli eventi avvenuti su qualsiasi bene virtualizzato.
Acquisizione informazioni di un “bene” attraverso il proprio smartphone fotografando il qrCode o avvicinando l’NFCTag associato tramite l’applicazione FlowItems.
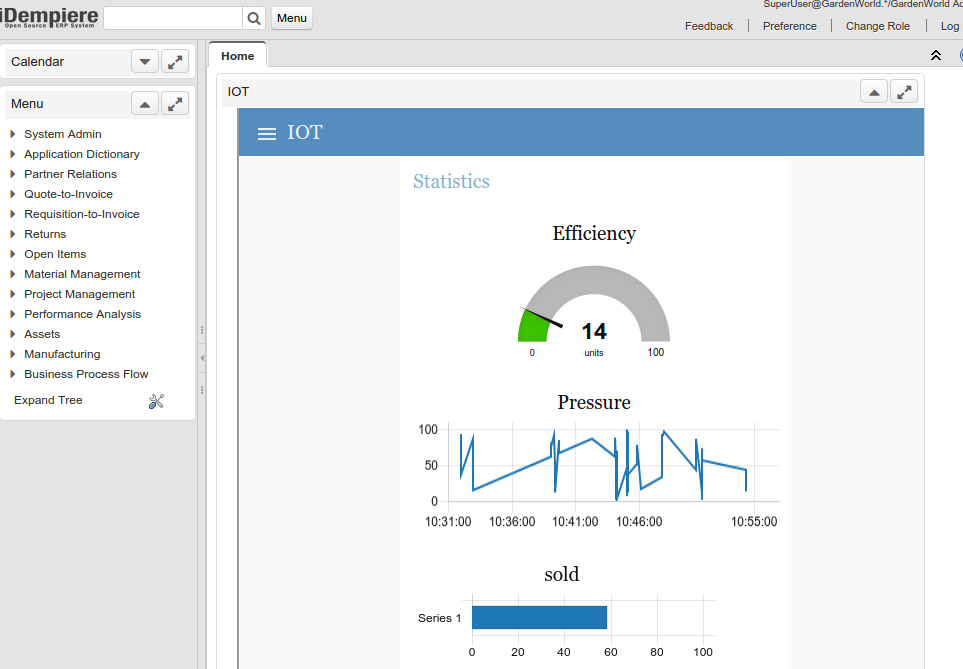
Dashboardcon analisi in tempo reale
NodeRed è il motore che gestisce i beni aziendali tramite protocolli standard e li mette in comunicazione con Idempiere attraverso i webservices.
RealTime analysis
Nel caso di gestione di macchine industriali questa soluzione rientra nelle specifiche dell’industria 4.0.
L’architettura del sistema è studiata per essere facilmente adattabile alle necessità di ogni cliente.
Molte delle app messe a disposizione integrano le funzionalità dello smartphone (GPS, navigatore, connettività) con le funzionalità dell’interfaccia ODB2.
Oltre a dare informazioni relative alla diagnosi dell’automobile, alla velocità, ai giri motori ecc.. le app sono in grado di tracciare il percorso dell’automobile, di definire lo stile di guida del conducente (accelerazioni, brusche frenate), il numero dei km effettuati…
tutto questo è possibile spendendo relativamente poco e può farlo chiunque sia dotato di un automobile.
La nostra soluzione integrata offre ulteriori funzionalità per la gestione del parco macchine.
Grazie alla connettività degli smartphone è possibile collegarsi istantaneamente al nostro servizio in cloud ed è possibile impostare il prossimo tagliando, il numero di km effettuati, chi e come viene utilizzata la macchina, il tempo medio di guida, il costo del carburante, i consumi, lo stato dell’automobile…inoltre il sistema avvisa attraverso “alert” (telegram o email) quando sta per scadere una revisione o quando l’auto ha bisogno di manutenzione. Attraverso l’interfaccia OBD2, se ci sono problemi, viene inviato un segnale in remoto che imposta lo stato della macchina “in manutenzione”.
Tutte le informazioni vengono messe a disposizione dal sistema con l’obiettivo di ottimizzare e controllare i costi attuali e futuri.
Oltre a questo, in qualsiasi momento, possiamo interagire con il sistema semplicemente avvicinando lo smartphone al tag NFC oppure scannerizzando il QRCode che viene associato al momento della creazione dell’anagrafica dell’automobile.
InformaticaGestionale.it da quando si occupa anche di IIOT (Industrial Internet Of Things) è alla ricerca di soluzioni che possono essere utili sopratutto alle esigenze dei nostri lettori (piccole e medie imprese manifatturiere o di servizio).
Sul mercato esistono già svariate soluzioni. Quello che vi proponiamo è l’integrazione di diverse software “eccellenti” ognuna per il proprio campo di applicazione. Il tutto offerto in modalità “cloud“.
Sfruttando protocolli riconosciuti a livello mondiale e tecnologie d’avanguardia siamo in grado di proporre un sistema che gestisce gli asset aziendali o le macchine industriali connettendole con il sistema integrato gestionale ERP.
Le nuove tecnologie, se ben integrate all’interno di un contesto aziendale, permettono un efficientamento dei flussi lavorativi ed un conseguente miglioramento delle performance su diversi KPI.
L’insieme dei sensori, degli attuatori, degli algoritmi per elaborazione dati, delle analisi e della creatività con i quali queste tecnologie interagiscono possono ridurre sensibilmente i costi dovuti a sprechi durante i processi aziendali e possono migliorare i tempi di processo.
La vera sfida è sfruttare le tecnologie esistenti in maniera intelligente evitando in tutti i modi l’overload informativo. Ovvero, avere più dati di quanti l’organizzazione sia capace di elaborare per trarne vantaggio.
L’eccesso informativo può essere infatti controproducente se non si riesce a gestire. L’impiego delle ultime tecnologie (capaci di generare dati in qualsiasi momento) e l’abbondanza dei dati aziendali richiedono l’impiego di avanzati sistemi di analisi.
I dati di per se, presi singolarmente, possono non essere significativi.
Per generare informazione “utile”, i dati devono essere associati tra loro in maniera intelligente e secondo alcune regole che determinano i contesti sui quali vengono analizzati (ad esempio, il dato “nome di una persona” se viene associata al dato “cliente” ci fornisce l’informazione che quella persona è un cliente. Oppure, se prendiamo il dato temperatura “T0” ed il dato “macchinaA” allora abbiamo l’informazione che la macchinaA ha una temperatura T0).
Prima di iniziare nuovi progetti informatici bisognerebbe anzitutto capire quali sono le reali esigenze aziendali. Fare uno studio dei processi e definire i KPI sui quali intervenire per avere miglioramenti sia nel breve che nel medio periodo.
Dopo di che, definire le tecnologie da adottare che supportino il raggiungimento degli obiettivi cercando di affidarsi a soluzioni più avanzate che hanno la caratteristica di interagire facilmente ed a bassi costi con sistemi eterogenei.
Da tenere in considerazione che uno dei fattori più critici delle tecnologie “passate” era la difficoltà di interagire con i sistemi eterogenei. Per fare integrazione tra diversi sistemi erano necessarie ore di analisi, sviluppo e di costante monitoraggio dei dati. Oggi, grazie all’impiego di standard affidabili e poco costosi di comunicazione, è possibile integrare i diversi sistemi in poco tempo e con limitati sviluppi.
Sperando di avervi dato altri spunti per vostri futuri progetti, se avete bisogno di altre informazioni, potete contattarci o scrivere commenti.
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Sempre attivo
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.
 hard
hard  economic
economic 

 medium
medium