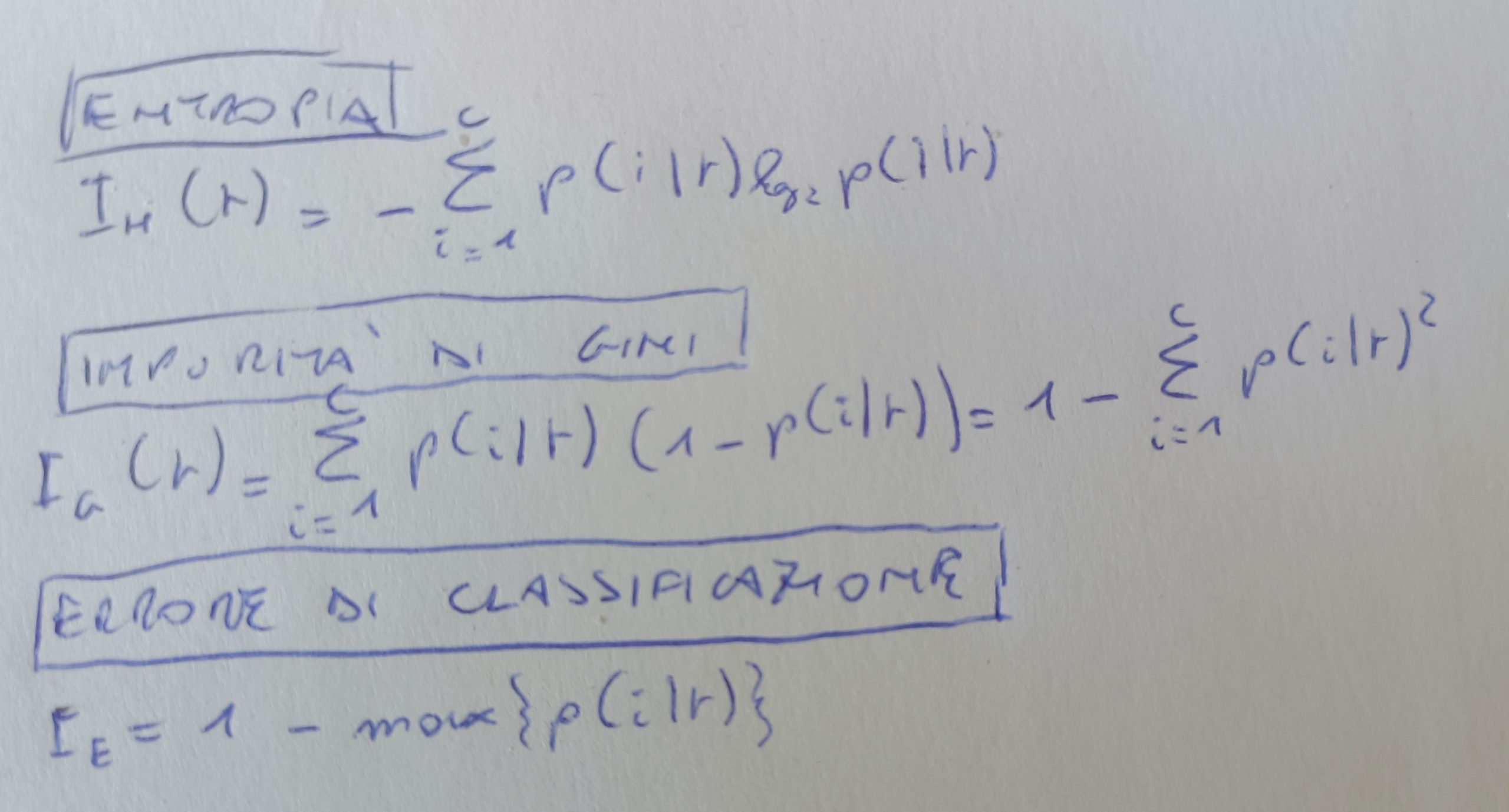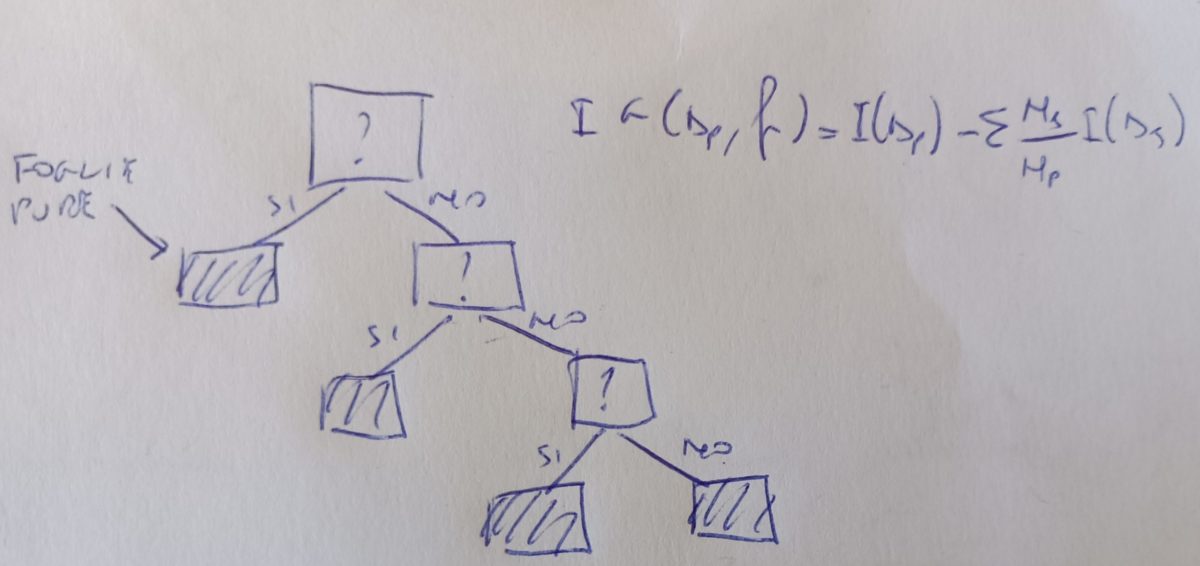
L’algoritmo ad apprendimento ad albero consiste nel trovare una serie di domande che consentono di suddividere il dataset dei dati sulla base della caratteristica che produce il massino guadagno informativo. Ad esempio, nel caso volessimo identificare se un campione di sangue è affetto da anemia perniciosa possiamo addestrare il modello ponendo domande sul volume medio dei globuli rossi (< 12?) e sulla quantità di vitamina B12 (<187?) (ovviamente non sono gli unici indicatori ed è un esempio solo illustrativo ma serve per avere un quadro della situazione). In base alle risposte possiamo etichettare i campioni nella classe corrispondente.
L’obiettivo è suddividere i campioni in modo da avere il massimo guadagno informativo IG.
Il guadagno informativo è descritto in questo modo:
IG(Dp,f)=I(Dp)-∑mj=1 Nj/Np I(Dj)
dove f è la carattersitica su cui si basa la suddivisione. Dp, Dj sono il datase del genitore e del j-esimo figlio. I è la misura di impurità. Np, Nj sono rispettivamente il numero di campioni dei genitori e del j-esimo figlio. Dall’equazione, minore è l’impurità dei figli e maggiore sarà il guadagno informativo.
Come individuiamo le impurità? generalmente vengono utilizzati 3 criteri di suddivisione o misure di impurità. Definendo p(i|t) come la proporzione dei campioni che appartengono al nodo t avremo:
Entropia Ih: è massima se tutti i campioni appartengono in maniera uniforme alle diverse classi. Considerando una classificazione binaria, sarà Ih= 1 se sono distruibuiti uniformemente per le due classi, quindi, p(i=1|t)=0,5. Sarà Ih=0 se tutti i campioni appartengono ad una o ad un’altra classe, quindi, p(i=1|t)=1 oppure P(i=0|t)=0. L’entropia cerca di massimizzare l’informazione reciproca all’interno di un albero.
Impurità di Gini Ig: cerca di minimizzare la probabilità di errori di classificazione. Maggiore è la mescolanza delle classi e maggiore sarà l’impurità di Gini.
Errore di classificazione Ie: utilizzato per la potatura di alberi decisionali. Se parto da un nodo padre e trovo un criterio di suddivisione che classifica tutti i campioni su una determinata classe, avrò diminuito le dimensioni dell’albero ma avrò aumentato l’errore di classificazione.