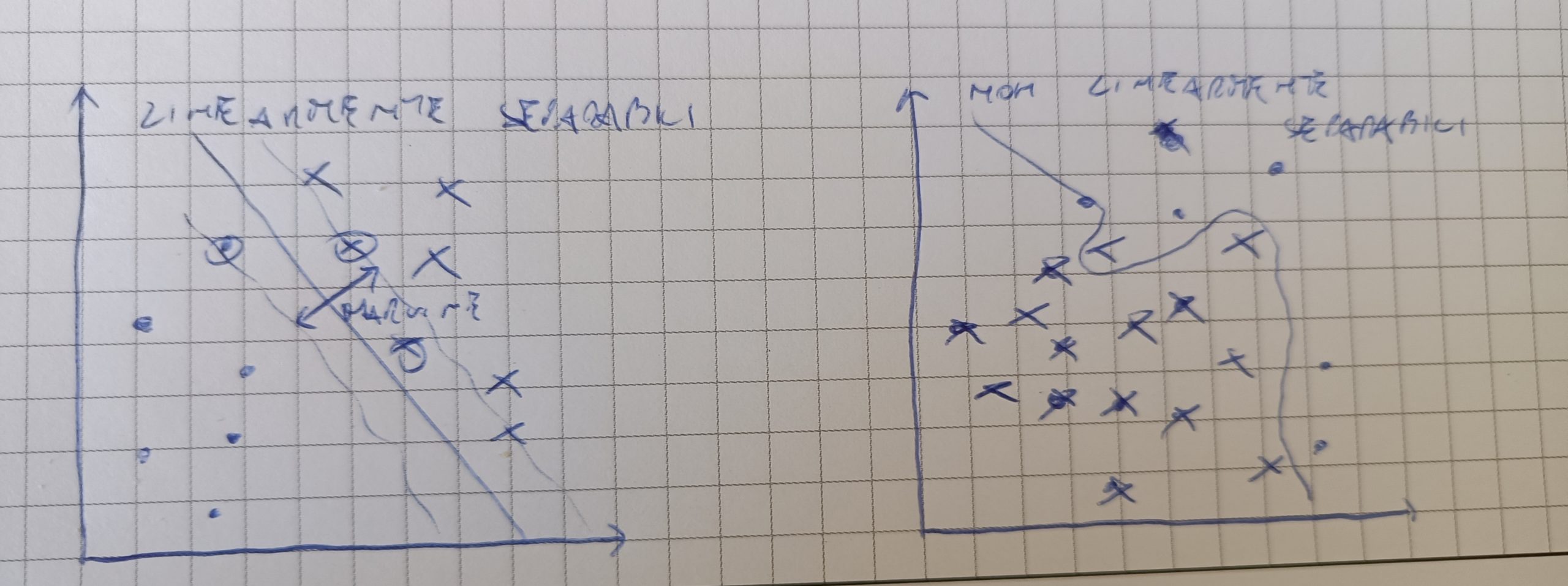
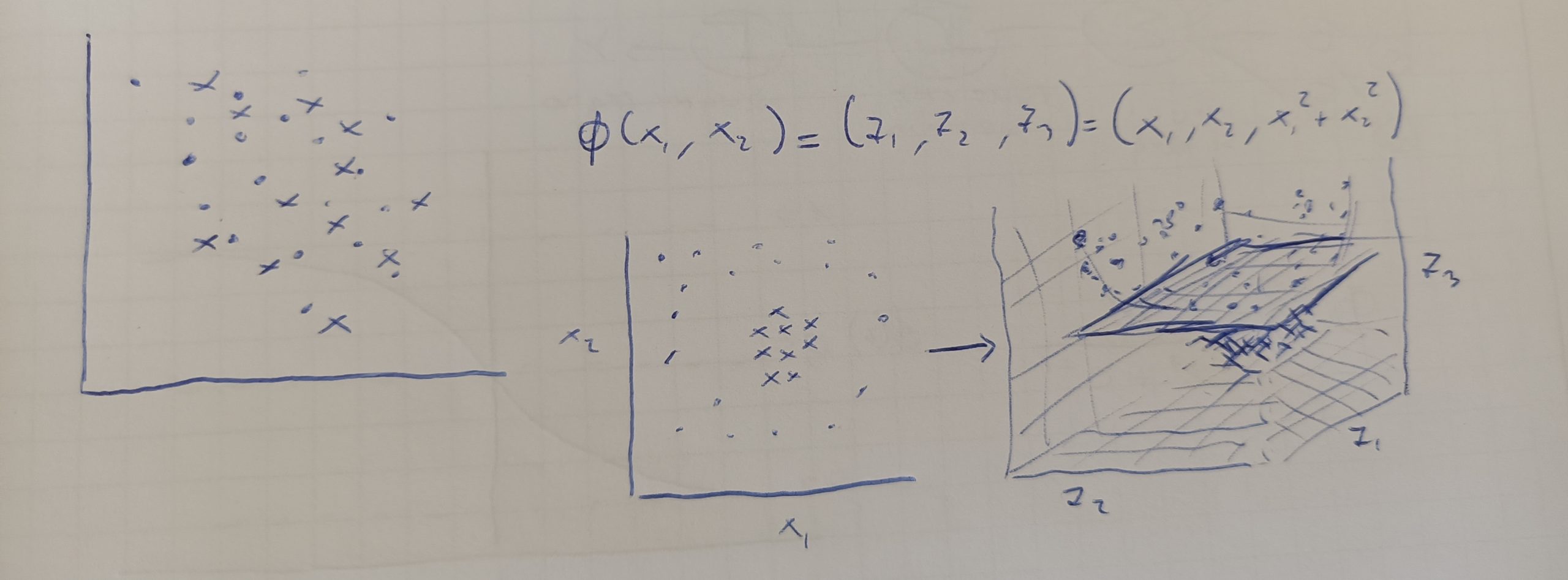
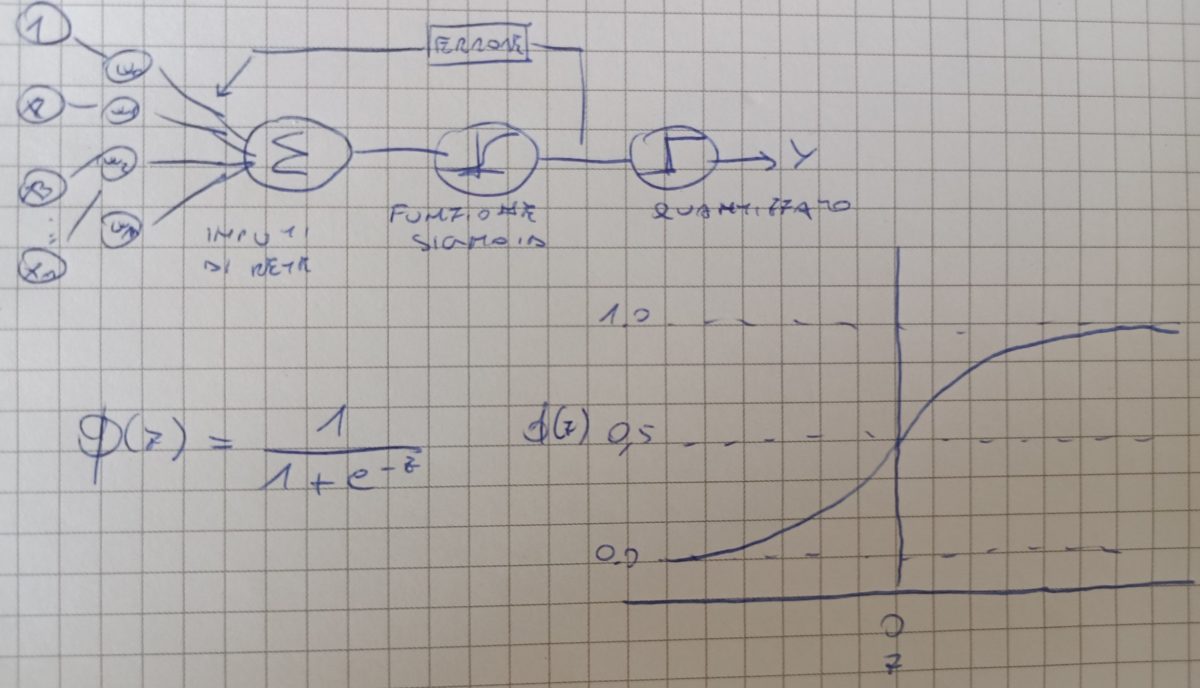
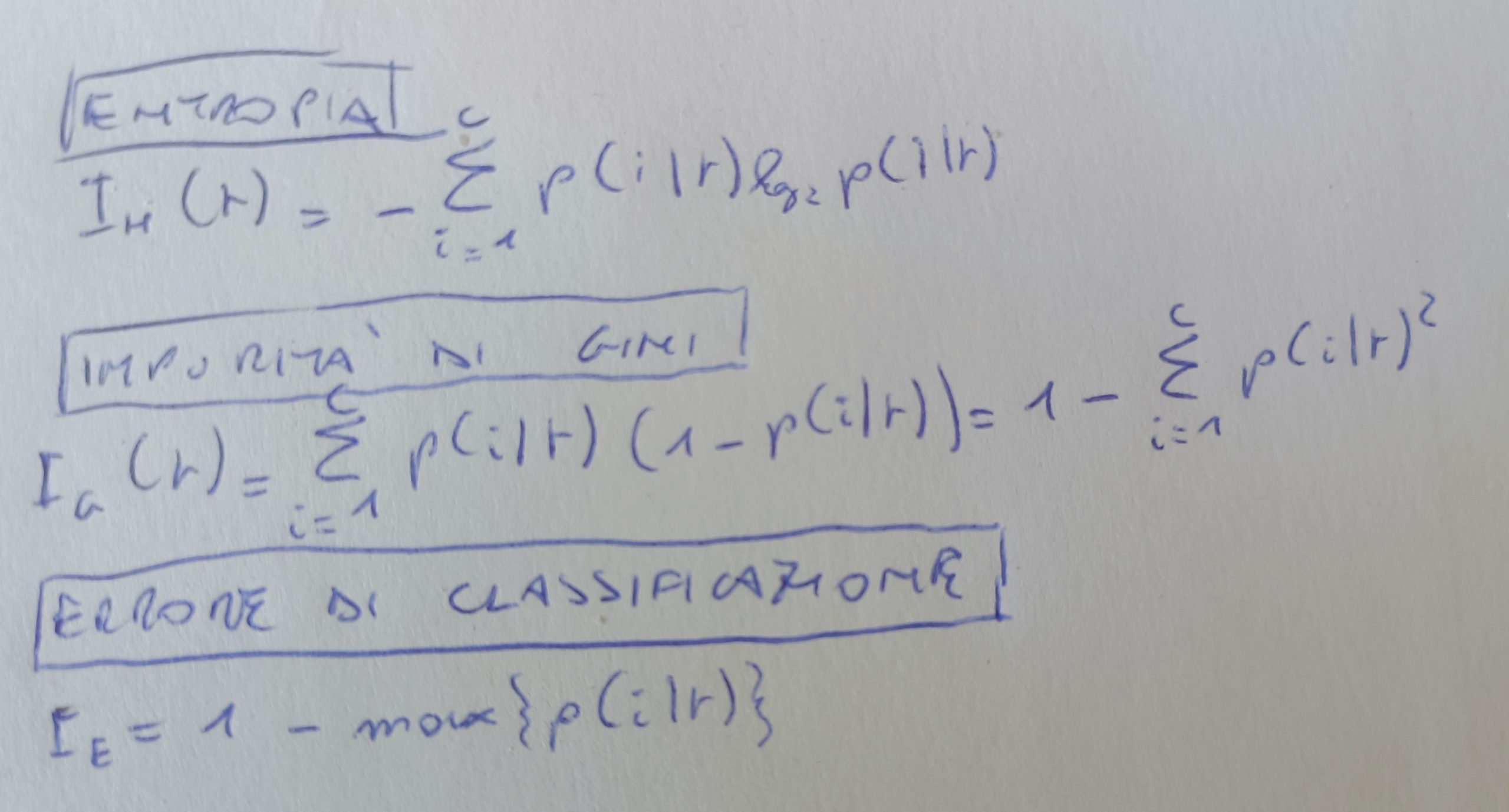Durante un progetto di Machine Learning è necessario valutare accuramente le performance del modello scelto per la predizione ed le probabilità di errore. In questo articolo valuteremo le performance dei principali modelli di predizione sul dataset Iris.
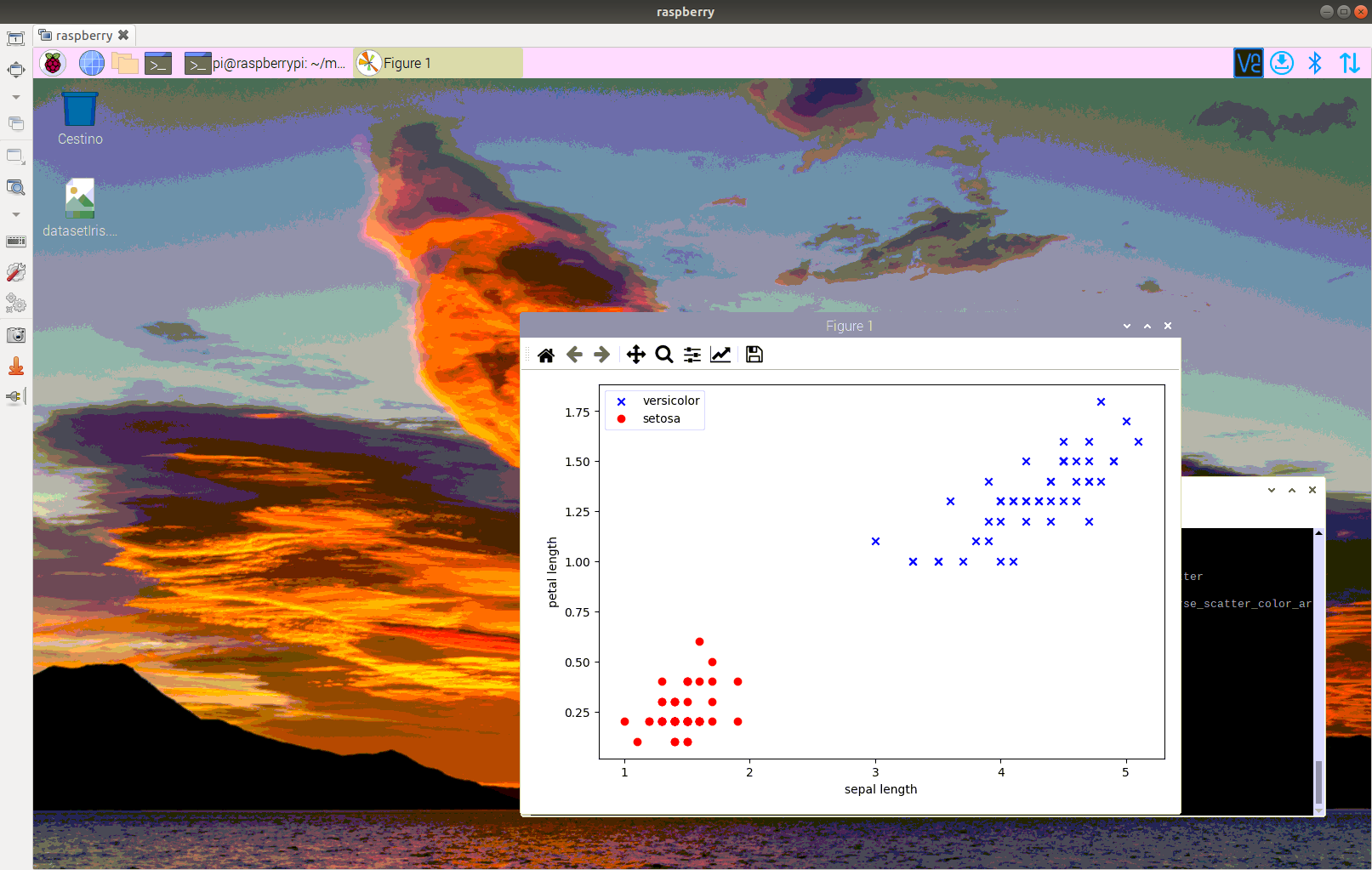
Prima di tutto preleviamo il dataset e esploriamo il campione dei dati attraverso il grafico delle distribuzioni delle caratteristiche sul target Species (pairplot)
df.head()
SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
df.describe()
count 150.000000 150.000000 150.000000 150.000000
mean 5.843333 3.054000 3.758667 1.198667
std 0.828066 0.433594 1.764420 0.763161
min 4.300000 2.000000 1.000000 0.100000
25% 5.100000 2.800000 1.600000 0.300000
50% 5.800000 3.000000 4.350000 1.300000
75% 6.400000 3.300000 5.100000 1.800000
max 7.900000 4.400000 6.900000 2.500000sns.pairplot(df,hue=’Species’)

Osservando le distribuzioni possiamo notare che la specie IrisSetosa è abbastanza distinta dalle altre due specie. Questo ci permetterà di utilizzare modelli che richiedono una distinzione netta tra le caratteristiche (es. perceptron).
Nell’ottica di studiare le performance per ciascun modello prendiamo in esame il dataset delle caratteristiche sepal length e sepal width ed il target Species. Suddividiamo il dataset in dati di training e di test con la funzione train test split.
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=40, test_size=0.3)Per ogni modello utilizzato costruiamo codice per l’apprendimento, per la predizione e per la performance.
def chooseModel(model,xtr,ytr,xt,yt):
model.fit(xtr, ytr)
y_model = model.predict(xt)
acc_model = accuracy_score(yt, y_model)
return round(acc_model,5)
#LOGISTIC REGRESSION
accuracy=chooseModel(LogisticRegression(),X_train,y_train,X_test,y_test)
print('Logistic Regression accuracy: %.2f',accuracy)
#MAX MARGIN KERNEL LINEAR low C parameter--> high BIAS
accuracy=chooseModel(SVC(kernel='linear', C=1.0, random_state=0),X_train,y_train,X_test,y_test)
print('Max Margin kernel linear accuracy (low C): %.2f',accuracy)
#MAX MARGIN KERNEL LINEAR high C parameter--> high BIAS
accuracy=chooseModel(SVC(kernel='linear', C=10.0, random_state=0),X_train,y_train,X_test,y_test)
print('Max Margin kernel linear accuracy (high C): %.2f',accuracy)
#MAX MARGIN KERNEL GAUSSIAN RBF NON LINEAR, LOW GAMMA --> MORBID DECISION REGION
accuracy=chooseModel(SVC(kernel='rbf', gamma=0.10, C=10.0, random_state=0),X_train,y_train,X_test,y_test)
print('Max Margin kernel gaussian accuracy (low gamma): %.2f',accuracy)
#MAX MARGIN KERNEL GAUSSIAN RBF NON LINEAR, HIGH GAMMA --> RIGID DECISION REGION
accuracy=chooseModel(SVC(kernel='rbf', gamma=0.20, C=10.0, random_state=0),X_train,y_train,X_test,y_test)
print('Max Margin kernel gaussian accuracy (high gamma): %.2f',accuracy)
#NEIGHBOR CLASSIFIER, LOW NUMBER NEIGHBOR
accuracy=chooseModel(KNeighborsClassifier(n_neighbors=3),X_train,y_train,X_test,y_test)
print('neighbor classifier accuracy (low neighbor): %.2f',accuracy)
#NEIGHBOR CLASSIFIER, HIGH NUMBER NEIGHBOR
accuracy=chooseModel(KNeighborsClassifier(n_neighbors=10),X_train,y_train,X_test,y_test)
print('neighbor classifier accuracy (high neighbor): %.2f',accuracy)
#DECISION TREE
accuracy=chooseModel(DecisionTreeClassifier(),X_train,y_train,X_test,y_test)
print('decision tree accuracy: %.2f',accuracy)
#RANDOM FOREST
accuracy=chooseModel(RandomForestClassifier(),X_train,y_train,X_test,y_test)
print('random forest accuracy: %.2f',accuracy)
#GRADIENT BOOSTING
accuracy=chooseModel(GradientBoostingClassifier(),X_train,y_train,X_test,y_test)
print('gradient boosting accuracy: %.2f',accuracy)
Questo il risultato dell’accuratezza degli algoritmi (per ogni singolo classificatore vi rimandiamo alle rispettive pagine di questo blog)
Logistic Regression accuracy: %.2f 0.86667
Max Margin kernel linear accuracy (low C): %.2f 0.86667
Max Margin kernel linear accuracy (high C): %.2f 0.84444
Max Margin kernel gaussian accuracy (low gamma): %.2f 0.82222
Max Margin kernel gaussian accuracy (high gamma): %.2f 0.77778
neighbor classifier accuracy (low neighbor): %.2f 0.77778
neighbor classifier accuracy (high neighbor): %.2f 0.77778
decision tree accuracy: %.2f 0.75556
random forest accuracy: %.2f 0.77778
gradient boosting accuracy: %.2f 0.71111
aggiungiamo alla nostra funzione il codice
print('******************')
print(classification_report(y_model, y_test))
print('******************')ed otteniamo questi risultati:
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 16
Iris-versicolor 0.86 0.75 0.80 16
Iris-virginica 0.73 0.85 0.79 13
accuracy 0.87 45
macro avg 0.86 0.87 0.86 45
weighted avg 0.87 0.87 0.87 45
******************
Logistic Regression accuracy: %.2f 0.86667
------------------
------------------
******************
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 16
Iris-versicolor 0.86 0.75 0.80 16
Iris-virginica 0.73 0.85 0.79 13
accuracy 0.87 45
macro avg 0.86 0.87 0.86 45
weighted avg 0.87 0.87 0.87 45
******************
Max Margin kernel linear accuracy (low C): %.2f 0.86667
------------------
------------------
******************
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 16
Iris-versicolor 0.79 0.73 0.76 15
Iris-virginica 0.73 0.79 0.76 14
accuracy 0.84 45
macro avg 0.84 0.84 0.84 45
weighted avg 0.85 0.84 0.84 45
******************
Max Margin kernel linear accuracy (high C): %.2f 0.84444
------------------
------------------
******************
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 16
Iris-versicolor 0.86 0.67 0.75 18
Iris-virginica 0.60 0.82 0.69 11
accuracy 0.82 45
macro avg 0.82 0.83 0.81 45
weighted avg 0.85 0.82 0.82 45
******************
Max Margin kernel gaussian accuracy (low gamma): %.2f 0.82222
------------------
------------------
******************
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 16
Iris-versicolor 0.86 0.60 0.71 20
Iris-virginica 0.47 0.78 0.58 9
accuracy 0.78 45
macro avg 0.77 0.79 0.76 45
weighted avg 0.83 0.78 0.79 45
******************
Max Margin kernel gaussian accuracy (high gamma): %.2f 0.77778
------------------
------------------
******************
precision recall f1-score support
Iris-setosa 1.00 0.94 0.97 17
Iris-versicolor 0.64 0.64 0.64 14
Iris-virginica 0.67 0.71 0.69 14
accuracy 0.78 45
macro avg 0.77 0.77 0.77 45
weighted avg 0.79 0.78 0.78 45
******************
neighbor classifier accuracy (low neighbor): %.2f 0.77778
------------------
------------------
******************
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 16
Iris-versicolor 0.86 0.60 0.71 20
Iris-virginica 0.47 0.78 0.58 9
accuracy 0.78 45
macro avg 0.77 0.79 0.76 45
weighted avg 0.83 0.78 0.79 45
******************
neighbor classifier accuracy (high neighbor): %.2f 0.77778
------------------
------------------
******************
precision recall f1-score support
Iris-setosa 1.00 0.94 0.97 17
Iris-versicolor 0.71 0.59 0.65 17
Iris-virginica 0.53 0.73 0.62 11
accuracy 0.76 45
macro avg 0.75 0.75 0.74 45
weighted avg 0.78 0.76 0.76 45
******************
decision tree accuracy: %.2f 0.75556
------------------
------------------
******************
precision recall f1-score support
Iris-setosa 1.00 0.94 0.97 17
Iris-versicolor 0.64 0.69 0.67 13
Iris-virginica 0.73 0.73 0.73 15
accuracy 0.80 45
macro avg 0.79 0.79 0.79 45
weighted avg 0.81 0.80 0.80 45
******************
random forest accuracy: %.2f 0.8
------------------
------------------
******************
precision recall f1-score support
Iris-setosa 0.94 0.94 0.94 16
Iris-versicolor 0.64 0.53 0.58 17
Iris-virginica 0.53 0.67 0.59 12
accuracy 0.71 45
macro avg 0.70 0.71 0.70 45
weighted avg 0.72 0.71 0.71 45
******************
gradient boosting accuracy: %.2f 0.71111