

Un’estensione del perceptron è la macchina a vettori di supporto. Mentre per il perceptron il nostro obiettivo era minimizzare gli errori di apprendimento, con la macchina SVM l’obiettivo è massimizzare il margine definito come distanza tra l’iperpiano di separazione ed i campioni più vicini a questo iperpiano (vettori di supporto).
Massimizzando il margine possiamo effettuare nuove predizioni semplicemente usando un sottoinsieme dei dati di training che rappresentano i vettori di supporto.
Massimizzare il margine è facilmente comprensibile per la classificazione di dati che sono linearmente separabili. Cosa succede invece per campioni che non sono linearmente separabili?
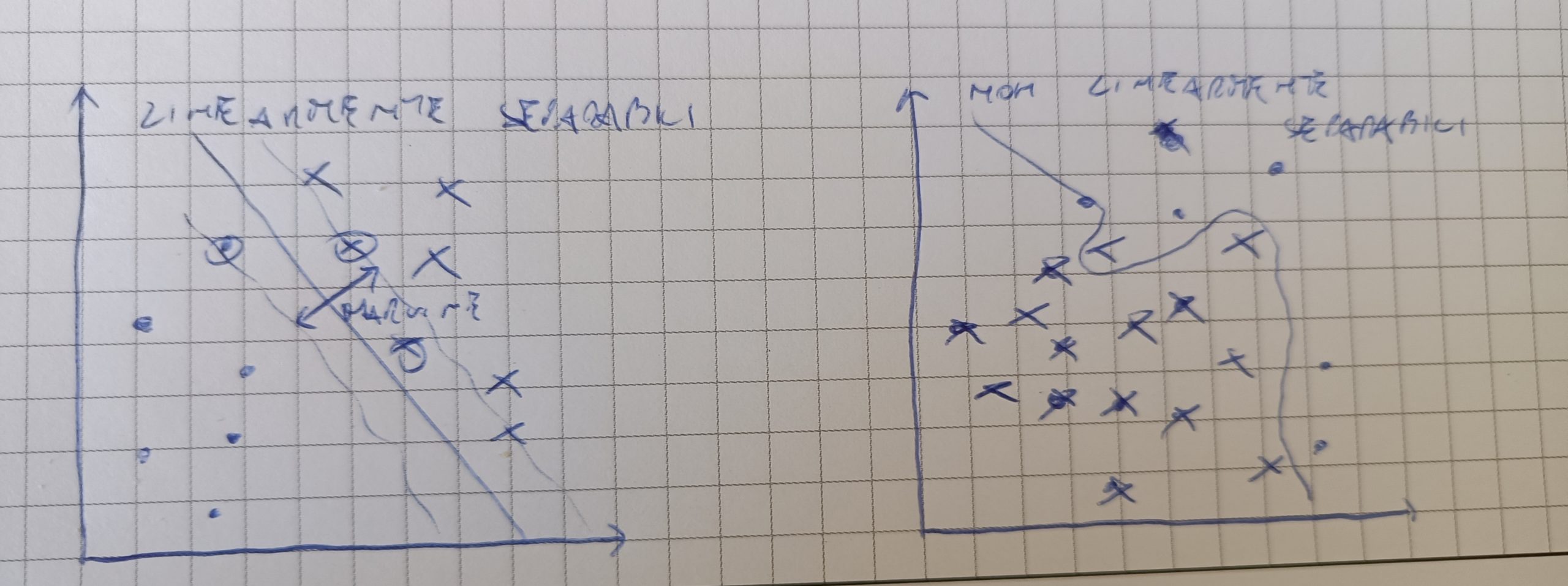
Per risolvere problemi di classificazione su campioni non lineari possiamo sfruttare l’algoritmo SVM in modo da kernizzarle su più dimensioni. L’obiettivo sarà di rappresentare i campioni non lineari con combinazioni tra i campioni in modo da aumentare la dimensionalità e cercare rappresentazioni non lineare ma con un marcato confine decisionale.
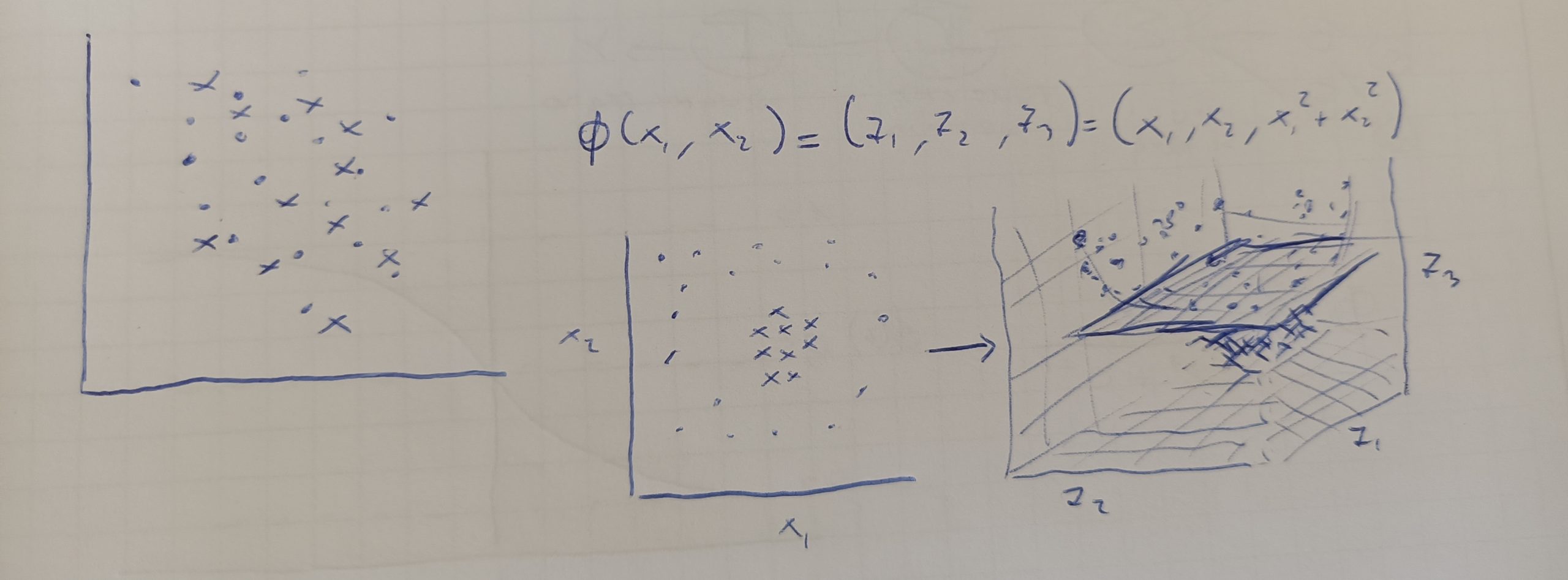
Come si vede nell’immagine abbiamo aumentato la dimensionalità del modello semplicemente utilizzando la relazione X12 + X22 . Questo ha permesso di identificare un nuovo iperpiani di separazione dei campioni (seconda figura).